
简介
什么是OneKE
OneKE是由蚂蚁集团和浙江大学联合研发的大模型知识抽取框架,具备中英文双语、多领域多任务的泛化知识抽取能力,并提供了完善的工具链支持。OneKE以开源形式贡献给OpenKG开放知识图谱社区。
基于非结构化文档的知识构建一直是知识图谱大规模落地的关键难题之一,因为真实世界的信息高度碎片化、非结构化,大语言模型在处理信息抽取任务时仍因抽取内容与自然语言表述之间的巨大差异导致效果不佳,自然语言文本信息表达中因隐式、长距离上下文关联存在较多的歧义、多义、隐喻等,给知识抽取任务带来较大的挑战。针对上述问题,蚂蚁集团与浙江大学依托多年积累的知识图谱与自然语言处理技术,联合构建和升级蚂蚁百灵大模型在知识抽取领域的能力,并发布中英双语大模型知识抽取框架OneKE,同时开源基于Chinese-Alpaca-2-13B全参数微调的版本。
下载地址:
HuggingFace ModelScope WiseModel
中英双语
数据的形式和质量是提升大模型能力的关键。针对不同领域、任务、语言的数据格式不统一问题,OneKE在训练前进行了数据的归一化与清洗。首先计算每个数据集的训练集、验证集和测试集内的文本重叠情况。如果发现一个文本实例在同一个文件中多次出现,并且伴随着不一致的标签,则移除该实例。其次,设计启发式规则以过滤低质量和无意义的数据:1)非字母字符占文本总量超过80%;2)文本长度不足五个字符且没有任何标签;3)高频出现的停用词,如‘the’、‘to’、‘of’等,超过80%。
更多
多领域多任务泛化
OneKE在指令微调训练过程中采用了“基于Schema的轮询指令构造”技术。先构建一个困难负样本字典,其键值对应的是Schema及其语义上相近的Schema集。难负样本的构建旨在促进语义近似的Schema更频繁地出现在指令中,同时也能在不牺牲性能的情况下减少训练样本量。然后,采取一种批次化指令生成方法,动态限制每条指令中询问的模式数量为N (其范围在4到6之间)。即使在评估阶段询问的Schema数目与训练时不同,通过轮询机制可以将询问数量平均分散至 N个,从而缓解泛化性能下降的问题。通过“基于Schema的轮询指令构造”技术,并融合开源及蚂蚁业务相关NER、RE、EE等近50个数据集可得到约0.4B tokens的大规模高质量抽取指令微调数据,其中部分数据已通过IEPile开源。
更多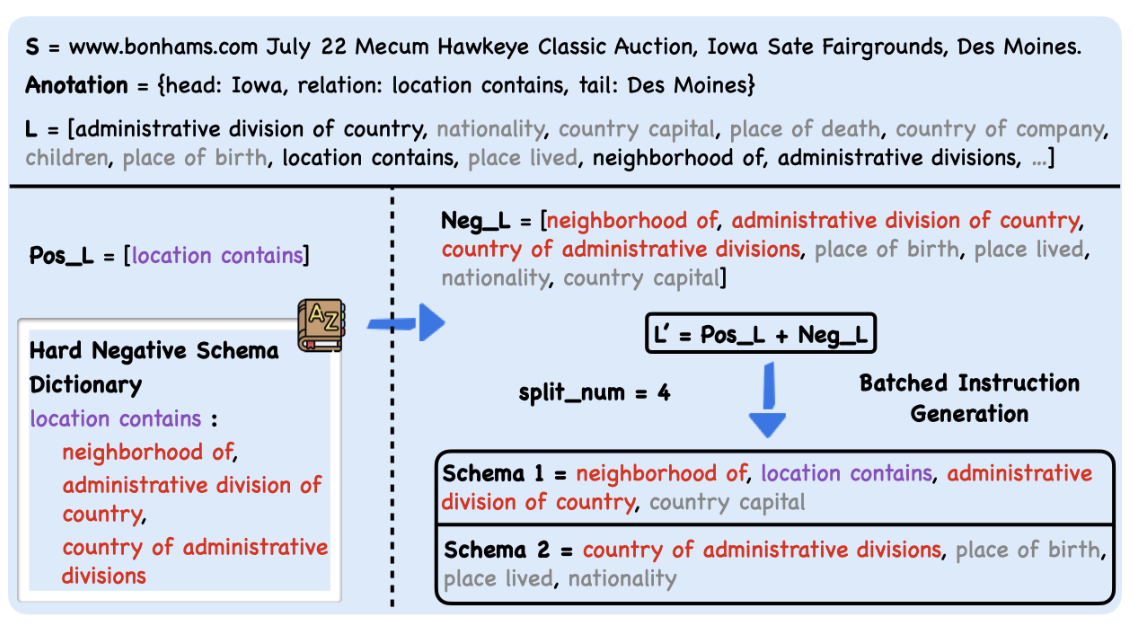
完善的工具链
目前可通过DeepKE-LLM或OpenSPG来直接使用OneKE。用户可以按照DeepKE-LLM项目指引完成环境配置、模型权重获取、数据转换后直接使用OneKE,DeepKE-LLM也支持对OneKE进行量化( 如4bit量化)以实现在低功耗设备上运行OneKE。 用户还可以按照OpenSPG项目指引完成环境配置、模型权重获取、数据转换后直接使用OneKE。用户按照OpenSPG结构定义Schema后,就可以运行知识抽取任务。
更多

如何使用OneKE?
OneKE中指令的格式采用了类JSON字符串的结构,本质上是一种字典类型的字符串,由以下三个字段构成: (1) 'instruction',即任务描述,以自然语言指定模型扮演的角色以及需要完成的任务; (2) 'schema',这是一份需提取的标签列表,明确指出了待抽取信息的关键字段,反应用户的需求,这是动态可变的; (3) 'input',指的是用于信息抽取的源文本。目前可通过DeepKE-LLM或OpenSPG来直接使用OneKE,高级用户可自行转换和构造指令使用OneKE。
注意:鉴于特定领域内信息抽取的复杂性和对提示的依赖程度较高,我们支持在指令中融入Schema描述和示例(Example)来提升抽取任务的效果。 由于模型规模有限,模型输出依赖于提示且不同的提示可能会产生不一致的结果,敬请谅解。
文献集
相关工作
论文列表
关于知识抽取、信息抽取的相关研究




局限性与不足
OneKE在全监督及多领域泛化性上有比较出色的表现,统一的指令结构也能让业务通过增加更多领域标注数据以获取更好的模型能力。通过OneKE框架,我们证明了基于大模型统一知识构建框架的可行性。然而,在实际的工业应用中,业务对知识要素的覆盖率、准确率要求非常高,统一Schema指令结构难以覆盖所有的知识表示形式,因此OneKE依然存在抽不全、抽不准以及难以处理较长文本的问题。由于模型的规模有限,模型输出极大地依赖于输入的提示词(Prompt)。因此,不同的尝试可能会产生不一致的结果,且可能存在幻觉输出。我们也在并行探索开放知识抽取,联动图谱自动构建系统,持续优化和提升OneKE新领域及新类型上的适应性。
致谢
我们对以下数据集构建者和维护者表示特别的谢意:AnatEM、BC2GM、BC4CHEMD、NCBI-Disease、BC5CDR、HarveyNER、CoNLL2003、GENIA、ACE2005、MIT Restaurant、MIT Movie、FabNER、MultiNERD、Ontonotes、FindVehicle、CrossNER、MSRA NER、Resume NER、CLUE NER、Weibo NER、Boson、ADE Corpus、GIDS、CoNLL2004、SciERC、Semeval-RE、NYT11-HRL、KBP37、NYT、Wiki-ZSL、FewRel、CMeIE、DuIE、COAE2016、IPRE、SKE2020、CASIE、PHEE、CrudeOilNews、RAMS、WikiEvents、DuEE、DuEE-Fin、FewFC、CCF law等,这些数据集极大地促进了领域发展。感谢MathPile和KnowledgePile项目提供的宝贵灵感。


















